
The moment you edit your campaign numbers directly, you’ve broken something important
It's a Tuesday. Finance sends you a message asking if you can move 30% of last quarter’s campaign spend from one category to another. The budget was approved under one initiative, but the actual work crossed over. Makes sense, right?
If your team handles this by opening up the reporting system and editing those numbers directly, you’ve just introduced a corruption into your data storage that will cause problems for years—and you’ll never see a warning pop up to tell you, you'll find out from a panicked call from your CPA.
This is one of the most common data integrity issues I encounter when I start working with marketing and product organizations. It’s everywhere, it’s almost always well-intentioned, and it’s almost entirely avoidable with the right architecture.
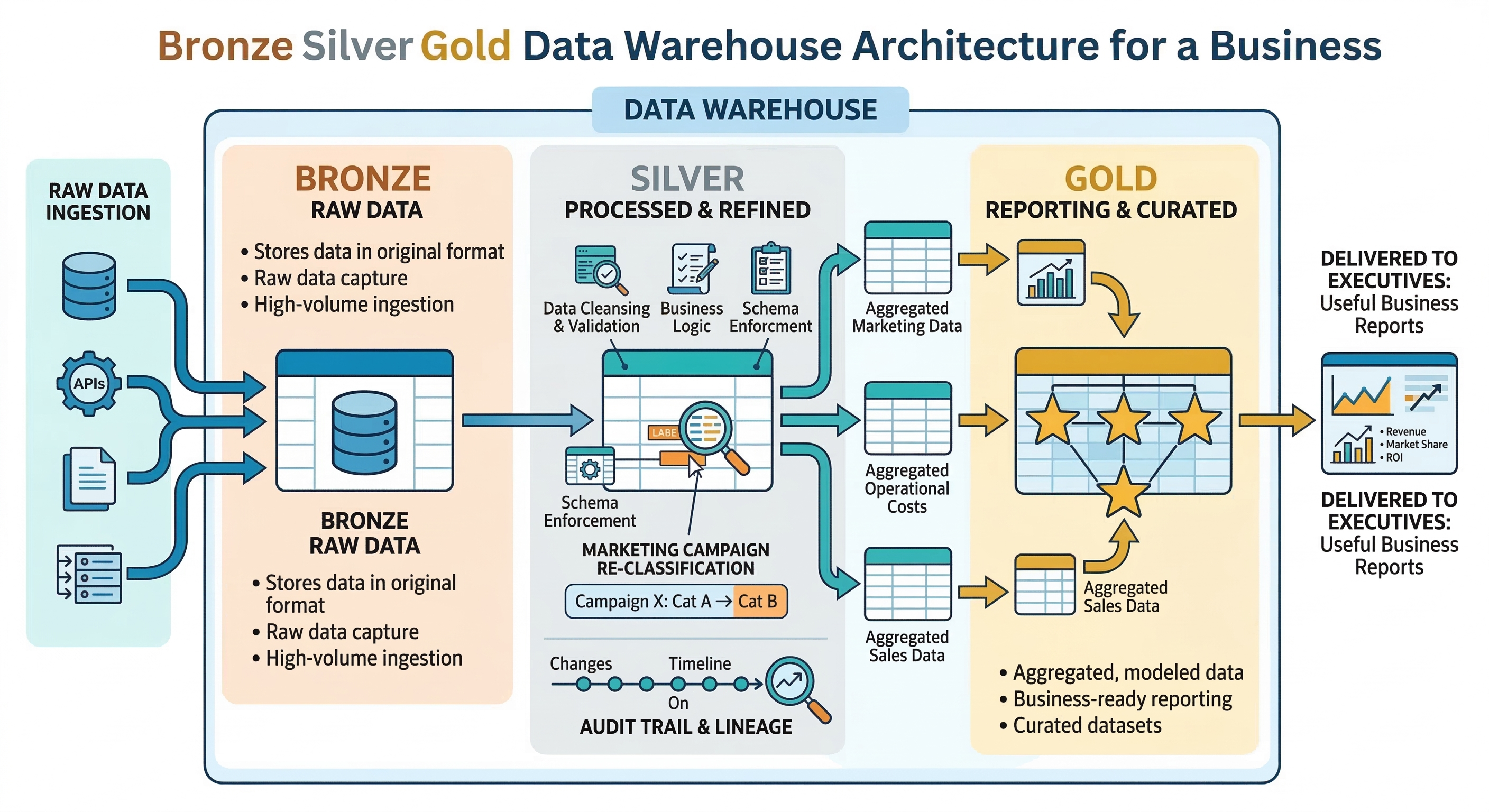
Raw data and processed data are not the same thing (and treating them as one is a trap)
There’s a distinction that matters a lot and gets collapsed in most analytics setups: raw data versus processed data.
Raw data is the record of what actually happened, as it was captured at the time. A campaign ran. Impressions were served. Clicks were tracked. Dollars were spent. This is your ground truth. History doesn’t change, and neither should this.
Processed data is what you do with that raw data. You aggregate it. You categorize it. You apply your attribution model. You run it through your internal taxonomy. You make it mean something in the context of your business. This layer is where interpretation lives—and interpretation can legitimately change over time.
The problem is that most organizations don’t keep these two layers separate. They have one version of the numbers, and when something needs to change—a reclassification, a correction, a retroactive budget reallocation—they edit that one version directly. The original record and the business interpretation collapse into a single thing, and nobody can tell where one ends and the other begins.
Once you collapse raw data and processed data into a single editable number, you lose the ability to ask what was true at any given point in time. And that question comes up more than you’d expect.
Retroactive changes are normal—the question is whether your architecture can handle them
Here’s the thing: retroactive changes to your analytics data aren’t unusual. They’re routine. And most of them are completely legitimate.
A campaign gets moved between product categories after a brand repositioning. Historical campaign names get updated to match a new naming convention. Someone discovers that last quarter’s numbers included a test campaign that should have been excluded from reporting. An attribution window gets updated to better reflect your actual sales cycle. These all happen. The question isn’t whether to allow retroactive changes—you should—but how your data architecture handles them.
An architecture that handles this well keeps raw data immutable. All reclassifications and corrections happen in a separate transformation layer, with a clear record of what changed, when, and who requested the change. If you run a query against last month’s data today, you get last month’s data as it existed last month. If you want to see the corrected version, you can do that too, but those are two different queries with two different answers—and the system knows the difference.
Most organizations don’t have this. They have one version of the data, and every edit overwrites the previous one. This seems simpler until you need to answer a question the overwritten data can’t answer anymore.

The audit trail problem
When you edit data directly, you lose the ability to answer a specific category of questions that tend to matter a lot:
What did we know, and when did we know it?
If campaign performance numbers were manually adjusted six months ago, and someone is now trying to understand a decision that was made based on the original figures, those original figures are gone. The institutional memory of what the data said at decision time doesn’t exist anymore.
This comes up in audits. It comes up in board presentations. It comes up in post-mortems where someone asks “why did we make this call?” and the data that informed the call has been quietly overwritten by subsequent corrections.
A subtler version of the same problem: A/B tests and experiments become unreliable if the underlying data gets retroactively modified. The entire point of a controlled experiment is that you’re comparing like to like. If the data has been altered—even legitimately—after the fact, your test results may no longer mean what you think they mean.
Storing raw data has a cost, and it’s worth it
The usual pushback on keeping raw data is cost. Storage isn’t free, and raw unprocessed data can be large. Why keep the original logs if you have processed summaries?
Because processed summaries are only as good as the logic that produced them—and that logic will change. When it does, you need the original records to reprocess from. If you’ve discarded the raw data, you can only go forward, not backward. You lose the ability to answer any historical question through any lens other than the one you had at the time you processed the data.
At modern data warehouse pricing, the cost of storing raw data is almost always small relative to the cost of not being able to answer important questions. I have yet to see an organization that regretted keeping it.
What good looks like
Organizations that manage this well use a layered approach: a raw data layer that nobody edits, a transformation layer where business logic is applied and version-controlled, and a reporting layer that surfaces results to dashboards and queries. Changes to business logic are documented and tracked. You can always see what the data looks like with the current interpretation and what it looked like with the old one.
Getting there doesn’t require rebuilding your entire data infrastructure. It requires a clearly drafted governance policy defining what raw data is for, and then the discipline to enforce your policy to protect your data consistently. That’s easier to put in place before bad habits form than after.
Have you ever needed to answer “what did our campaign data look like six months ago, before the reclassification”—and not been able to? That’s the exact problem this kind of architecture prevents. I’d love to hear how your organization currently handles retroactive corrections.
If this is a challenge you’re actively dealing with, reach out. This is exactly the kind of thing I help marketing and product teams get right.

Chat with the author
If you'd like to make a connection and perhaps collaborate on something:I'd love to talk with you!No matter if you want to build your professional network,or think there might be a great opportunity to to work together or partner.